Tutorial: Building a Domain
Tutorials > Building a Domain > Part 5
Creating a State Visualizer
It is often the case that you will want to visualize states of your domain in various contexts. For example, maybe you want to interact with the environment, acting as the agent yourself, or maybe you want to review episodes generated from a learning agent or a policy. BURLAP provides standard interfaces and tools for doing these kinds of things. Specifically, BURLAP provides a MultiLayerRenderer object that is a JPanel. It maintains a list of RenderLayer objects that paint to the graphics context of the MultiLayerRenderer (or rather, an offscreen buffer of it) in the order of the RenderLayers (i.e., painters algorithm). One of the more common RenderLayer instances is the StateRenderLayer, used to render a state. StateRenderLayer holds a current State to paint, which can be updated externally, and a list of StatePainter instances that, similar to a RenderLayer, are interfaces that are provided a State and Graphics2D context to which an aspect of the state is painted. Also useful is the Visualizer class, an extension of MultiLayerRenderer that is assumed to contain a StateRenderLayer and provides quick access methods for updating the State of the StateRenderLayer to render. A UML diagram of these classes is shown below.
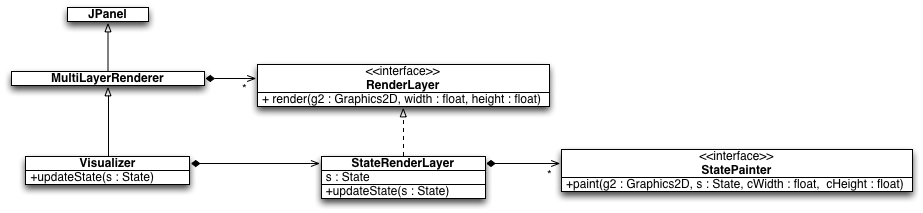
Figure: UML Digram of the Java interfaces/classes for visualization.
Therefore, the standard way to provide state visualization in BURLAP, is to implement one or more StatePainters, which can then be added to a StateRenderLayer used by a Visualizer. For our grid world, we will create two StatePainter implementations, one for drawing the walls of our grid world, and another for drawing the location of the agent. We'll make these inner classes of our ExampleGridWorld class.
public class WallPainter implements StatePainter {
public void paint(Graphics2D g2, State s, float cWidth, float cHeight) {
//walls will be filled in black
g2.setColor(Color.BLACK);
//set up floats for the width and height of our domain
float fWidth = ExampleGridWorld.this.map.length;
float fHeight = ExampleGridWorld.this.map[0].length;
//determine the width of a single cell
//on our canvas such that the whole map can be painted
float width = cWidth / fWidth;
float height = cHeight / fHeight;
//pass through each cell of our map and if it's a wall, paint a black rectangle on our
//cavas of dimension widthxheight
for(int i = 0; i < ExampleGridWorld.this.map.length; i++){
for(int j = 0; j < ExampleGridWorld.this.map[0].length; j++){
//is there a wall here?
if(ExampleGridWorld.this.map[i][j] == 1){
//left coordinate of cell on our canvas
float rx = i*width;
//top coordinate of cell on our canvas
//coordinate system adjustment because the java canvas
//origin is in the top left instead of the bottom right
float ry = cHeight - height - j*height;
//paint the rectangle
g2.fill(new Rectangle2D.Float(rx, ry, width, height));
}
}
}
}
}
public class AgentPainter implements StatePainter {
@Override
public void paint(Graphics2D g2, State s,
float cWidth, float cHeight) {
//agent will be filled in gray
g2.setColor(Color.GRAY);
//set up floats for the width and height of our domain
float fWidth = ExampleGridWorld.this.map.length;
float fHeight = ExampleGridWorld.this.map[0].length;
//determine the width of a single cell on our canvas
//such that the whole map can be painted
float width = cWidth / fWidth;
float height = cHeight / fHeight;
int ax = (Integer)s.get(VAR_X);
int ay = (Integer)s.get(VAR_Y);
//left coordinate of cell on our canvas
float rx = ax*width;
//top coordinate of cell on our canvas
//coordinate system adjustment because the java canvas
//origin is in the top left instead of the bottom right
float ry = cHeight - height - ay*height;
//paint the rectangle
g2.fill(new Ellipse2D.Float(rx, ry, width, height));
}
}
There is nothing fancy going on in this code. In the case of the AgentPainter, we get the x and y variable values of the agent, get their position in screen space, and draw a circle. We do something similar for the wall painter, but iterate over our map drawing black rectangles wherever a wall is present.
Finally, lets add some methods to our ExampleGridWorld class for packaging instances of these painters into a StateRenderLayer and a Visualizer.
public StateRenderLayer getStateRenderLayer(){
StateRenderLayer rl = new StateRenderLayer();
rl.addStatePainter(new ExampleGridWorld.WallPainter());
rl.addStatePainter(new ExampleGridWorld.AgentPainter());
return rl;
}
public Visualizer getVisualizer(){
return new Visualizer(this.getStateRenderLayer());
}
Testing it Out
Now that we've made all the pieces of our domain, lets test it out! A good way to test out a domain is to create a VisualExplorer that lets you act as the agent and see the state of the world through a Visualizer. Add the following main method to our ExampleGridWorldClass.
public static void main(String [] args){
ExampleGridWorld gen = new ExampleGridWorld();
gen.setGoalLocation(10, 10);
SADomain domain = gen.generateDomain();
State initialState = new EXGridState(0, 0);
SimulatedEnvironment env = new SimulatedEnvironment(domain, initialState);
Visualizer v = gen.getVisualizer();
VisualExplorer exp = new VisualExplorer(domain, env, v);
exp.addKeyAction("w", ACTION_NORTH, "");
exp.addKeyAction("s", ACTION_SOUTH, "");
exp.addKeyAction("d", ACTION_EAST, "");
exp.addKeyAction("a", ACTION_WEST, "");
exp.initGUI();
}
The first block of code instantiates our domain with the goal state set to 10, 10 (the top right corner); creates an initial state with the agent in location 0, 0; and creates a Simulated Environment around our domain. The environment could be used for any number of purposes, including using it with learning algorithms. Here, we use it as the domain we'll explore with a VisualExplorer that visualizes states with the Visualizer components we defined earlier. The addKeyAction methods let us set up key bindings to execute actions in the environment. The arguments of this method correspond to the key you want to send the action, the name of the ActionType, and a String representation of the parameters of the action, which we leave empty since our actions are unparameterized. (Another variant of this method will let you specify the direct Action object you want it to use, rather than generating the Action from an ActionType identified by its name). Finally, the initGUI() method will start the VisualExplorer.
When you run the ExampleGridWorld class, the visual explorer should pop up, which will look like the below image.

Figure: Screenshot of the VisualExplorer that will launch.
If you use the w-a-s-d keys, you can control the agent's movements in the environment. Note that because we made our grid world stochastic, sometimes the agent will go in a different direction than the action you selected! This is precisely the kind of mechanics that a learning agent would experience, given the definition of the MDP we made.
One other element of the VisualExplorer you might want to experiment with is the shell, which you can open with the "Show Shell" button, which will bring up a text box and field you can use to send special commands for working with an environment. If you want a list of commands that are available in the shell, enter "cmds". Most commands also include help information, which you can get by entering the command with the -h option. To see an example of something you can do with the shell, try changing the agent's position in the environment to 3,2 by entering the command:
setVar x 3 y 2
and you should see that the agent in the visualizer appears in the specified location! You can also add your own commands to a BURLAP shell, by implementing the ShellCommand interface, and adding it to the shell. You can get the shell of a VisualExplorer with the method getShell() and you can add ShellCommands to it with the method addCommand(ShellCommand). The shell is a powerful tool for controlling runtime experimentation.
Conclusion
That's it! We've now walked you through how you can implement your own MDP in BURLAP that can be used with the various learning and planning algorithms. We also showed you how to create a visualizer for them and how to interact with them. There is another tutorial specifically about creating MDPs that use the object-oriented MDP state representation, but this is an advanced optional rich state representation and you should be able to get by fine with standard MDP definitions.
Final Code
ExampleGridWorld.java
import burlap.mdp.auxiliary.DomainGenerator;
import burlap.mdp.core.StateTransitionProb;
import burlap.mdp.core.TerminalFunction;
import burlap.mdp.core.action.Action;
import burlap.mdp.core.action.UniversalActionType;
import burlap.mdp.core.state.State;
import burlap.mdp.singleagent.SADomain;
import burlap.mdp.singleagent.environment.SimulatedEnvironment;
import burlap.mdp.singleagent.model.FactoredModel;
import burlap.mdp.singleagent.model.RewardFunction;
import burlap.mdp.singleagent.model.statemodel.FullStateModel;
import burlap.shell.visual.VisualExplorer;
import burlap.visualizer.StatePainter;
import burlap.visualizer.StateRenderLayer;
import burlap.visualizer.Visualizer;
import java.awt.*;
import java.awt.geom.Ellipse2D;
import java.awt.geom.Rectangle2D;
import java.util.ArrayList;
import java.util.List;
public class ExampleGridWorld implements DomainGenerator {
public static final String VAR_X = "x";
public static final String VAR_Y = "y";
public static final String ACTION_NORTH = "north";
public static final String ACTION_SOUTH = "south";
public static final String ACTION_EAST = "east";
public static final String ACTION_WEST = "west";
protected int goalx = 10;
protected int goaly = 10;
//ordered so first dimension is x
protected int [][] map = new int[][]{
{0,0,0,0,0,1,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0,0,0},
{0,0,0,0,0,1,0,0,0,0,0},
{0,0,0,0,0,1,0,0,0,0,0},
{0,0,0,0,0,1,0,0,0,0,0},
{1,0,1,1,1,1,1,1,0,1,1},
{0,0,0,0,1,0,0,0,0,0,0},
{0,0,0,0,1,0,0,0,0,0,0},
{0,0,0,0,0,0,0,0,0,0,0},
{0,0,0,0,1,0,0,0,0,0,0},
{0,0,0,0,1,0,0,0,0,0,0},
};
public void setGoalLocation(int goalx, int goaly){
this.goalx = goalx;
this.goaly = goaly;
}
@Override
public SADomain generateDomain() {
SADomain domain = new SADomain();
domain.addActionTypes(
new UniversalActionType(ACTION_NORTH),
new UniversalActionType(ACTION_SOUTH),
new UniversalActionType(ACTION_EAST),
new UniversalActionType(ACTION_WEST));
GridWorldStateModel smodel = new GridWorldStateModel();
RewardFunction rf = new ExampleRF(this.goalx, this.goaly);
TerminalFunction tf = new ExampleTF(this.goalx, this.goaly);
domain.setModel(new FactoredModel(smodel, rf, tf));
return domain;
}
public StateRenderLayer getStateRenderLayer(){
StateRenderLayer rl = new StateRenderLayer();
rl.addStatePainter(new ExampleGridWorld.WallPainter());
rl.addStatePainter(new ExampleGridWorld.AgentPainter());
return rl;
}
public Visualizer getVisualizer(){
return new Visualizer(this.getStateRenderLayer());
}
protected class GridWorldStateModel implements FullStateModel{
protected double [][] transitionProbs;
public GridWorldStateModel() {
this.transitionProbs = new double[4][4];
for(int i = 0; i < 4; i++){
for(int j = 0; j < 4; j++){
double p = i != j ? 0.2/3 : 0.8;
transitionProbs[i][j] = p;
}
}
}
@Override
public List<StateTransitionProb> stateTransitions(State s, Action a) {
//get agent current position
EXGridState gs = (EXGridState)s;
int curX = gs.x;
int curY = gs.y;
int adir = actionDir(a);
List<StateTransitionProb> tps = new ArrayList<StateTransitionProb>(4);
StateTransitionProb noChange = null;
for(int i = 0; i < 4; i++){
int [] newPos = this.moveResult(curX, curY, i);
if(newPos[0] != curX || newPos[1] != curY){
//new possible outcome
EXGridState ns = gs.copy();
ns.x = newPos[0];
ns.y = newPos[1];
//create transition probability object and add to our list of outcomes
tps.add(new StateTransitionProb(ns, this.transitionProbs[adir][i]));
}
else{
//this direction didn't lead anywhere new
//if there are existing possible directions
//that wouldn't lead anywhere, aggregate with them
if(noChange != null){
noChange.p += this.transitionProbs[adir][i];
}
else{
//otherwise create this new state and transition
noChange = new StateTransitionProb(s.copy(), this.transitionProbs[adir][i]);
tps.add(noChange);
}
}
}
return tps;
}
@Override
public State sample(State s, Action a) {
s = s.copy();
EXGridState gs = (EXGridState)s;
int curX = gs.x;
int curY = gs.y;
int adir = actionDir(a);
//sample direction with random roll
double r = Math.random();
double sumProb = 0.;
int dir = 0;
for(int i = 0; i < 4; i++){
sumProb += this.transitionProbs[adir][i];
if(r < sumProb){
dir = i;
break; //found direction
}
}
//get resulting position
int [] newPos = this.moveResult(curX, curY, dir);
//set the new position
gs.x = newPos[0];
gs.y = newPos[1];
//return the state we just modified
return gs;
}
protected int actionDir(Action a){
int adir = -1;
if(a.actionName().equals(ACTION_NORTH)){
adir = 0;
}
else if(a.actionName().equals(ACTION_SOUTH)){
adir = 1;
}
else if(a.actionName().equals(ACTION_EAST)){
adir = 2;
}
else if(a.actionName().equals(ACTION_WEST)){
adir = 3;
}
return adir;
}
protected int [] moveResult(int curX, int curY, int direction){
//first get change in x and y from direction using 0: north; 1: south; 2:east; 3: west
int xdelta = 0;
int ydelta = 0;
if(direction == 0){
ydelta = 1;
}
else if(direction == 1){
ydelta = -1;
}
else if(direction == 2){
xdelta = 1;
}
else{
xdelta = -1;
}
int nx = curX + xdelta;
int ny = curY + ydelta;
int width = ExampleGridWorld.this.map.length;
int height = ExampleGridWorld.this.map[0].length;
//make sure new position is valid (not a wall or off bounds)
if(nx < 0 || nx >= width || ny < 0 || ny >= height ||
ExampleGridWorld.this.map[nx][ny] == 1){
nx = curX;
ny = curY;
}
return new int[]{nx,ny};
}
}
public class WallPainter implements StatePainter {
public void paint(Graphics2D g2, State s, float cWidth, float cHeight) {
//walls will be filled in black
g2.setColor(Color.BLACK);
//set up floats for the width and height of our domain
float fWidth = ExampleGridWorld.this.map.length;
float fHeight = ExampleGridWorld.this.map[0].length;
//determine the width of a single cell
//on our canvas such that the whole map can be painted
float width = cWidth / fWidth;
float height = cHeight / fHeight;
//pass through each cell of our map and if it's a wall, paint a black rectangle on our
//cavas of dimension widthxheight
for(int i = 0; i < ExampleGridWorld.this.map.length; i++){
for(int j = 0; j < ExampleGridWorld.this.map[0].length; j++){
//is there a wall here?
if(ExampleGridWorld.this.map[i][j] == 1){
//left coordinate of cell on our canvas
float rx = i*width;
//top coordinate of cell on our canvas
//coordinate system adjustment because the java canvas
//origin is in the top left instead of the bottom right
float ry = cHeight - height - j*height;
//paint the rectangle
g2.fill(new Rectangle2D.Float(rx, ry, width, height));
}
}
}
}
}
public class AgentPainter implements StatePainter {
@Override
public void paint(Graphics2D g2, State s,
float cWidth, float cHeight) {
//agent will be filled in gray
g2.setColor(Color.GRAY);
//set up floats for the width and height of our domain
float fWidth = ExampleGridWorld.this.map.length;
float fHeight = ExampleGridWorld.this.map[0].length;
//determine the width of a single cell on our canvas
//such that the whole map can be painted
float width = cWidth / fWidth;
float height = cHeight / fHeight;
int ax = (Integer)s.get(VAR_X);
int ay = (Integer)s.get(VAR_Y);
//left coordinate of cell on our canvas
float rx = ax*width;
//top coordinate of cell on our canvas
//coordinate system adjustment because the java canvas
//origin is in the top left instead of the bottom right
float ry = cHeight - height - ay*height;
//paint the rectangle
g2.fill(new Ellipse2D.Float(rx, ry, width, height));
}
}
public static class ExampleRF implements RewardFunction {
int goalX;
int goalY;
public ExampleRF(int goalX, int goalY){
this.goalX = goalX;
this.goalY = goalY;
}
@Override
public double reward(State s, Action a, State sprime) {
int ax = (Integer)s.get(VAR_X);
int ay = (Integer)s.get(VAR_Y);
//are they at goal location?
if(ax == this.goalX && ay == this.goalY){
return 100.;
}
return -1;
}
}
public static class ExampleTF implements TerminalFunction {
int goalX;
int goalY;
public ExampleTF(int goalX, int goalY){
this.goalX = goalX;
this.goalY = goalY;
}
@Override
public boolean isTerminal(State s) {
//get location of agent in next state
int ax = (Integer)s.get(VAR_X);
int ay = (Integer)s.get(VAR_Y);
//are they at goal location?
if(ax == this.goalX && ay == this.goalY){
return true;
}
return false;
}
}
public static void main(String [] args){
ExampleGridWorld gen = new ExampleGridWorld();
gen.setGoalLocation(10, 10);
SADomain domain = gen.generateDomain();
State initialState = new EXGridState(0, 0);
SimulatedEnvironment env = new SimulatedEnvironment(domain, initialState);
Visualizer v = gen.getVisualizer();
VisualExplorer exp = new VisualExplorer(domain, env, v);
exp.addKeyAction("w", ACTION_NORTH, "");
exp.addKeyAction("s", ACTION_SOUTH, "");
exp.addKeyAction("d", ACTION_EAST, "");
exp.addKeyAction("a", ACTION_WEST, "");
exp.initGUI();
}
}
ExGridState.java
import burlap.mdp.core.state.MutableState;
import burlap.mdp.core.state.StateUtilities;
import burlap.mdp.core.state.UnknownKeyException;
import burlap.mdp.core.state.annotations.DeepCopyState;
import java.util.Arrays;
import java.util.List;
import static edu.brown.cs.burlap.tutorials.domain.simple.ExampleGridWorld.VAR_X;
import static edu.brown.cs.burlap.tutorials.domain.simple.ExampleGridWorld.VAR_Y;
@DeepCopyState
public class EXGridState implements MutableState{
public int x;
public int y;
private final static List<Object> keys = Arrays.<Object>asList(VAR_X, VAR_Y);
public EXGridState() {
}
public EXGridState(int x, int y) {
this.x = x;
this.y = y;
}
@Override
public MutableState set(Object variableKey, Object value) {
if(variableKey.equals(VAR_X)){
this.x = StateUtilities.stringOrNumber(value).intValue();
}
else if(variableKey.equals(VAR_Y)){
this.y = StateUtilities.stringOrNumber(value).intValue();
}
else{
throw new UnknownKeyException(variableKey);
}
return this;
}
public List<Object> variableKeys() {
return keys;
}
@Override
public Object get(Object variableKey) {
if(variableKey.equals(VAR_X)){
return x;
}
else if(variableKey.equals(VAR_Y)){
return y;
}
throw new UnknownKeyException(variableKey);
}
@Override
public EXGridState copy() {
return new EXGridState(x, y);
}
@Override
public String toString() {
return StateUtilities.stateToString(this);
}
}