Tutorial: Basic Planning and Learning
Tutorials > Basic Planning and Learning > Part 6
- Introduction
- Creating the class shell
- Initializing the data members
- Setting up a result visualizer
- Planning with BFS
- Planning with DFS
- Planning with A*
- Planning with Value Iteration
- Learning with Q-Learning
- Learning with Sarsa(λ)
- Live Visualization
- Value Function and Policy Visualization
- Experimenter Tools and Performance Plotting
- Conclusion
Experimenter Tools and Performance Plotting
In the previous section you learned how to use an EnvironmentObserver to perform live visualization of the agent in the state space as it was learning. In this section we will make use another EnvironmentObserver called PerformancePlotter to record a learning algorithm's performance and compare it to another learning algorithm. The PerformacnePlotter has a lot of powerful tools to display lots of important experimental results. To streamline the construction process, we will make use of the LearningAlgorithmExperimenter class, which is convenient for comparing the performance of multiple learning algorithms over many trials. If you'd prefer to run your own experiment using a different design flow, however, you could make use of the PerformancePlotter directly yourself.
To demonstrate the LearningAlgorithmExperimenter, we will compare the learning performance of a Q-learning algorithm with the performance of a SARSA(λ) algorithm. To make the results a bit more interesting to visualize, we will also use a different reward function than we have been that returns a reward of 5 when the goal is reached and -0.1 for every other step.
Lets then begin by adding a new method to our BasicBehavior class to call to test the experimenter tools. Inside the method, we will change our domain's reward function. To do so, we will exploit the fact that the model for our grid world is a FactoredModel; a model that has individual components for the reward function, terminal states, and state transition model. This is also the kind of model the vast majority of domains in BURLAP use. Since it is a FactoredModel, we can retreive it from our domain, and change its reward function. We'll use a GoalBasedRF that returns a value 5 for transitions to our goal state and -0.1 everywhere else.
public void experimenterAndPlotter(){
//different reward function for more structured performance plots
((FactoredModel)domain.getModel()).setRf(new GoalBasedRF(this.goalCondition, 5.0, -0.1));
}
For the LearningAlgorithmExperimenter to report an average performance of each algorithm, it will test the algorithm over multiple trials. Therefore, at the start of each trial a clean agent instance of the algorithm without knowledge of any of the previous trials must be generated. To easily get a clean version of each agent, the LearningAlgorithmExperimenter will request a sequence of LearningAgentFactory objects that can be used to generate a clean version of each agent on demand. In the following code, we create a LearningAgentFactory for a Q-learning algorithm and a SARSA(λ) algorithm.
/**
* Create factories for Q-learning agent and SARSA agent to compare
*/
LearningAgentFactory qLearningFactory = new LearningAgentFactory() {
public String getAgentName() {
return "Q-Learning";
}
public LearningAgent generateAgent() {
return new QLearning(domain, 0.99, hashingFactory, 0.3, 0.1);
}
};
LearningAgentFactory sarsaLearningFactory = new LearningAgentFactory() {
public String getAgentName() {
return "SARSA";
}
public LearningAgent generateAgent() {
return new SarsaLam(domain, 0.99, hashingFactory, 0.0, 0.1, 1.);
}
};
Note that the factory also requires a getAgentName() method to be implemented. The LearningAgentExperimenter class will use this name to label the results of each learning algorithm's performance.
We are just about ready to create our experimenter, but first we will need to decide how many trials we want to test, the length of the trials, and what performance data we want to plot. There are six possible performance metrics we could plot:
- cumulative reward per step,
- cumulative reward per episode,
- average reward per episode,
- median reward per episode,
- cumulative steps per episode, and
- steps per episode.
Furthermore, we could also have our plotter display the results from the most recent trial only, the average performance across all trials, or both. For this tutorial, we will plot both the most recent trial and average trial performance for the cumulative steps per episode and the average reward per episode. We will also test the algorithms for 10 trials that last 100 episodes each. The below code will create our experimenter, start it, and also save all the data for all six metrics to CSV files.
LearningAlgorithmExperimenter exp = new LearningAlgorithmExperimenter(env, 10, 100,
qLearningFactory, sarsaLearningFactory);
exp.setUpPlottingConfiguration(500, 250, 2, 1000,
TrialMode.MOST_RECENT_AND_AVERAGE,
PerformanceMetric.CUMULATIVE_STEPS_PER_EPISODE,
PerformanceMetric.AVERAGE_EPISODE_REWARD);
exp.startExperiment();
exp.writeStepAndEpisodeDataToCSV("expData");
Note that in the constructor, the LearningAgent factories are the last parameters, of which a variable number of factories could be provided; we could have tested just one agent, or we could have tested many more, but there should naturally always be at least one LearningAgentFactory provided.
The other important part of the code is the setUpPlottingConfiguration method, which is used to define what results are plotted and how they are displayed. The first four parameters specify a plot's width and height, the number of columns of plots, and the maximum window height. In this case, plots are set to be 500x200, with two columns of plots. Plots are placed columns first, wrapping down to a new row as needed. The window size will be scaled to the width of plots times the number of columns; the height will scale to the height of the plots times the number of rows, unless that height is greater than the maximum window height, in which case the plots will be placed in a scroll view. The next parameter specifies whether to show plots for only the most recent trial, the average performance over all trials, or both. We have selected to show both. The remaining parameters are variable in size and specify which performance metrics will be plotted. The order of the performance metrics provided also dictates the order that the plots will fill the window (again, filling columns first).
The startExperiment method begins the experiment which will run all trials for all learning algorithms provided.
Once you point our BasicBevhavior main method to the new method we've created and run the code, A GUI should appear with the plots requested, displaying the performance as it is available. When the experiment is complete, you should be left with an image like the below.
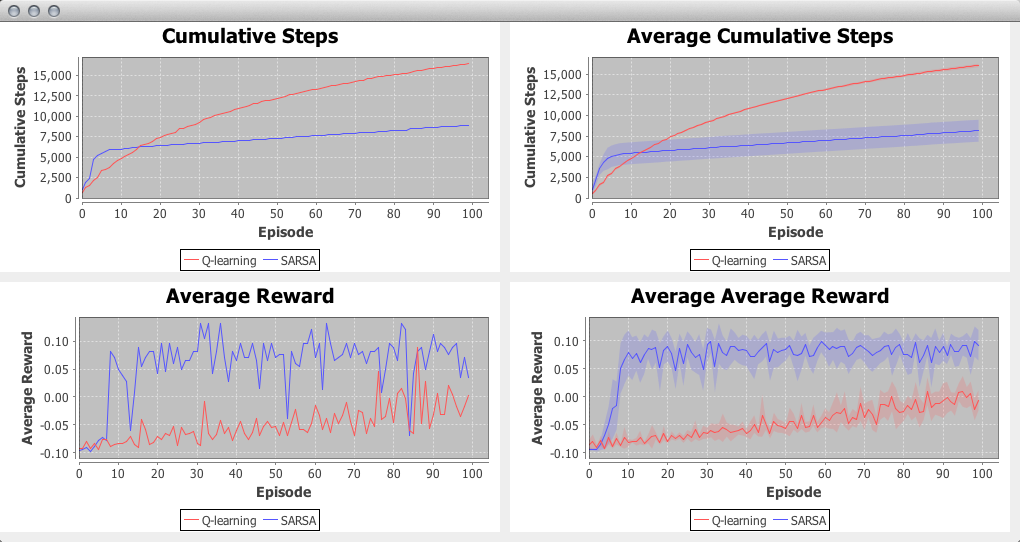
In the trial average plots, you'll note that a translucent filled area around each of the curves is present. This filled area shows the 95% confidence interval. You can change the significance level used before running the experiment using the setPlotCISignificance method.
Note that these plots are not static and you can interact with them. If you click drag in a region, it will cause the plot to zoom into the selected area. If you right click, you'll find a number of other options that you can set, including changing the labels. Another important feature you'll see from the contextual menu is an option to save plot image to disk.
Since we also told the LearningAlgorithmExperimenter object to save the data to csv files, you should find two files that it created: expDataSteps.csv and expDataEpisodes.csv. The first contains all trial data for the cumulative reward per step metric. The latter contains all of the episode-wise metric data (even for the metrics that we did not plot). These files will make interacting with the data in another program, such as R, convenient.
Conclusion
This ends our tutorial on implementing basic planning and learning algorithms in BURLAP. There are other planning and learning algorithms in BURLAP, but hopefully this tutorial has explained the core concepts well enough that you should be able to try different algorithms easily. As a future exercise, we encourage you to try just that within this code you've created! The complete set of code that we wrote in this tutorial is shown below for your convenience.
The full code is also in the BURLAP code libary under the examples package.
import burlap.behavior.policy.GreedyQPolicy;
import burlap.behavior.policy.Policy;
import burlap.behavior.policy.PolicyUtils;
import burlap.behavior.singleagent.Episode;
import burlap.behavior.singleagent.auxiliary.EpisodeSequenceVisualizer;
import burlap.behavior.singleagent.auxiliary.StateReachability;
import burlap.behavior.singleagent.auxiliary.performance.LearningAlgorithmExperimenter;
import burlap.behavior.singleagent.auxiliary.performance.PerformanceMetric;
import burlap.behavior.singleagent.auxiliary.performance.TrialMode;
import burlap.behavior.singleagent.auxiliary.valuefunctionvis.ValueFunctionVisualizerGUI;
import burlap.behavior.singleagent.auxiliary.valuefunctionvis.common.ArrowActionGlyph;
import burlap.behavior.singleagent.auxiliary.valuefunctionvis.common.LandmarkColorBlendInterpolation;
import burlap.behavior.singleagent.auxiliary.valuefunctionvis.common.PolicyGlyphPainter2D;
import burlap.behavior.singleagent.auxiliary.valuefunctionvis.common.StateValuePainter2D;
import burlap.behavior.singleagent.learning.LearningAgent;
import burlap.behavior.singleagent.learning.LearningAgentFactory;
import burlap.behavior.singleagent.learning.tdmethods.QLearning;
import burlap.behavior.singleagent.learning.tdmethods.SarsaLam;
import burlap.behavior.singleagent.planning.Planner;
import burlap.behavior.singleagent.planning.deterministic.DeterministicPlanner;
import burlap.behavior.singleagent.planning.deterministic.informed.Heuristic;
import burlap.behavior.singleagent.planning.deterministic.informed.astar.AStar;
import burlap.behavior.singleagent.planning.deterministic.uninformed.bfs.BFS;
import burlap.behavior.singleagent.planning.deterministic.uninformed.dfs.DFS;
import burlap.behavior.singleagent.planning.stochastic.valueiteration.ValueIteration;
import burlap.behavior.valuefunction.QFunction;
import burlap.behavior.valuefunction.ValueFunction;
import burlap.domain.singleagent.gridworld.GridWorldDomain;
import burlap.domain.singleagent.gridworld.GridWorldTerminalFunction;
import burlap.domain.singleagent.gridworld.GridWorldVisualizer;
import burlap.domain.singleagent.gridworld.state.GridAgent;
import burlap.domain.singleagent.gridworld.state.GridLocation;
import burlap.domain.singleagent.gridworld.state.GridWorldState;
import burlap.mdp.auxiliary.stateconditiontest.StateConditionTest;
import burlap.mdp.auxiliary.stateconditiontest.TFGoalCondition;
import burlap.mdp.core.TerminalFunction;
import burlap.mdp.core.state.State;
import burlap.mdp.core.state.vardomain.VariableDomain;
import burlap.mdp.singleagent.common.GoalBasedRF;
import burlap.mdp.singleagent.common.VisualActionObserver;
import burlap.mdp.singleagent.environment.SimulatedEnvironment;
import burlap.mdp.singleagent.model.FactoredModel;
import burlap.mdp.singleagent.oo.OOSADomain;
import burlap.statehashing.HashableStateFactory;
import burlap.statehashing.simple.SimpleHashableStateFactory;
import burlap.visualizer.Visualizer;
import java.awt.*;
import java.util.List;
public class BasicBehavior {
GridWorldDomain gwdg;
OOSADomain domain;
TerminalFunction tf;
StateConditionTest goalCondition;
State initialState;
HashableStateFactory hashingFactory;
SimulatedEnvironment env;
public BasicBehavior(){
gwdg = new GridWorldDomain(11, 11);
gwdg.setMapToFourRooms();
tf = new GridWorldTerminalFunction(10, 10);
gwdg.setTf(tf);
goalCondition = new TFGoalCondition(tf);
domain = gwdg.generateDomain();
initialState = new GridWorldState(new GridAgent(0, 0), new GridLocation(10, 10, "loc0"));
hashingFactory = new SimpleHashableStateFactory();
env = new SimulatedEnvironment(domain, initialState);
//VisualActionObserver observer = new VisualActionObserver(domain,
// GridWorldVisualizer.getVisualizer(gwdg.getMap()));
//observer.initGUI();
//env.addObservers(observer);
}
public void visualize(String outputpath){
Visualizer v = GridWorldVisualizer.getVisualizer(gwdg.getMap());
new EpisodeSequenceVisualizer(v, domain, outputpath);
}
public void BFSExample(String outputPath){
DeterministicPlanner planner = new BFS(domain, goalCondition, hashingFactory);
Policy p = planner.planFromState(initialState);
PolicyUtils.rollout(p, initialState, domain.getModel()).write(outputPath + "bfs");
}
public void DFSExample(String outputPath){
DeterministicPlanner planner = new DFS(domain, goalCondition, hashingFactory);
Policy p = planner.planFromState(initialState);
PolicyUtils.rollout(p, initialState, domain.getModel()).write(outputPath + "dfs");
}
public void AStarExample(String outputPath){
Heuristic mdistHeuristic = new Heuristic() {
public double h(State s) {
GridAgent a = ((GridWorldState)s).agent;
double mdist = Math.abs(a.x-10) + Math.abs(a.y-10);
return -mdist;
}
};
DeterministicPlanner planner = new AStar(domain, goalCondition,
hashingFactory, mdistHeuristic);
Policy p = planner.planFromState(initialState);
PolicyUtils.rollout(p, initialState, domain.getModel()).write(outputPath + "astar");
}
public void valueIterationExample(String outputPath){
Planner planner = new ValueIteration(domain, 0.99, hashingFactory, 0.001, 100);
Policy p = planner.planFromState(initialState);
PolicyUtils.rollout(p, initialState, domain.getModel()).write(outputPath + "vi");
simpleValueFunctionVis((ValueFunction)planner, p);
//manualValueFunctionVis((ValueFunction)planner, p);
}
public void qLearningExample(String outputPath){
LearningAgent agent = new QLearning(domain, 0.99, hashingFactory, 0., 1.);
//run learning for 50 episodes
for(int i = 0; i < 50; i++){
Episode e = agent.runLearningEpisode(env);
e.write(outputPath + "ql_" + i);
System.out.println(i + ": " + e.maxTimeStep());
//reset environment for next learning episode
env.resetEnvironment();
}
}
public void sarsaLearningExample(String outputPath){
LearningAgent agent = new SarsaLam(domain, 0.99, hashingFactory, 0., 0.5, 0.3);
//run learning for 50 episodes
for(int i = 0; i < 50; i++){
Episode e = agent.runLearningEpisode(env);
e.write(outputPath + "sarsa_" + i);
System.out.println(i + ": " + e.maxTimeStep());
//reset environment for next learning episode
env.resetEnvironment();
}
}
public void simpleValueFunctionVis(ValueFunction valueFunction, Policy p){
List<State> allStates = StateReachability.getReachableStates(
initialState, domain, hashingFactory);
ValueFunctionVisualizerGUI gui = GridWorldDomain.getGridWorldValueFunctionVisualization(
allStates, 11, 11, valueFunction, p);
gui.initGUI();
}
public void manualValueFunctionVis(ValueFunction valueFunction, Policy p){
List<State> allStates = StateReachability.getReachableStates(
initialState, domain, hashingFactory);
//define color function
LandmarkColorBlendInterpolation rb = new LandmarkColorBlendInterpolation();
rb.addNextLandMark(0., Color.RED);
rb.addNextLandMark(1., Color.BLUE);
//define a 2D painter of state values,
//specifying which attributes correspond to the x and y coordinates of the canvas
StateValuePainter2D svp = new StateValuePainter2D(rb);
svp.setXYKeys("agent:x", "agent:y",
new VariableDomain(0, 11), new VariableDomain(0, 11),
1, 1);
//create our ValueFunctionVisualizer that paints for all states
//using the ValueFunction source and the state value painter we defined
ValueFunctionVisualizerGUI gui = new ValueFunctionVisualizerGUI(
allStates, svp, valueFunction);
//define a policy painter that uses arrow glyphs for each of the grid world actions
PolicyGlyphPainter2D spp = new PolicyGlyphPainter2D();
spp.setXYKeys("agent:x", "agent:y", new VariableDomain(0, 11),
new VariableDomain(0, 11),
1, 1);
spp.setActionNameGlyphPainter(GridWorldDomain.ACTION_NORTH, new ArrowActionGlyph(0));
spp.setActionNameGlyphPainter(GridWorldDomain.ACTION_SOUTH, new ArrowActionGlyph(1));
spp.setActionNameGlyphPainter(GridWorldDomain.ACTION_EAST, new ArrowActionGlyph(2));
spp.setActionNameGlyphPainter(GridWorldDomain.ACTION_WEST, new ArrowActionGlyph(3));
spp.setRenderStyle(PolicyGlyphPainter2D.PolicyGlyphRenderStyle.DISTSCALED);
//add our policy renderer to it
gui.setSpp(spp);
gui.setPolicy(p);
//set the background color for places where states are not rendered to grey
gui.setBgColor(Color.GRAY);
//start it
gui.initGUI();
}
public void experimentAndPlotter(){
//different reward function for more structured performance plots
((FactoredModel)domain.getModel()).setRf(new GoalBasedRF(this.goalCondition, 5.0, -0.1));
/**
* Create factories for Q-learning agent and SARSA agent to compare
*/
LearningAgentFactory qLearningFactory = new LearningAgentFactory() {
public String getAgentName() {
return "Q-Learning";
}
public LearningAgent generateAgent() {
return new QLearning(domain, 0.99, hashingFactory, 0.3, 0.1);
}
};
LearningAgentFactory sarsaLearningFactory = new LearningAgentFactory() {
public String getAgentName() {
return "SARSA";
}
public LearningAgent generateAgent() {
return new SarsaLam(domain, 0.99, hashingFactory, 0.0, 0.1, 1.);
}
};
LearningAlgorithmExperimenter exp = new LearningAlgorithmExperimenter(
env, 10, 100, qLearningFactory, sarsaLearningFactory);
exp.setUpPlottingConfiguration(500, 250, 2, 1000,
TrialMode.MOST_RECENT_AND_AVERAGE,
PerformanceMetric.CUMULATIVE_STEPS_PER_EPISODE,
PerformanceMetric.AVERAGE_EPISODE_REWARD);
exp.startExperiment();
exp.writeStepAndEpisodeDataToCSV("expData");
}
public static void main(String[] args) {
BasicBehavior example = new BasicBehavior();
String outputPath = "output/";
example.BFSExample(outputPath);
//example.DFSExample(outputPath);
//example.AStarExample(outputPath);
//example.valueIterationExample(outputPath);
//example.qLearningExample(outputPath);
//example.sarsaLearningExample(outputPath);
//example.experimentAndPlotter();
example.visualize(outputPath);
}
}