Tutorial: Basic Planning and Learning
Tutorials (v1) > Basic Planning and Learning > Part 1
- Introduction
- Creating the class shell
- Initializing the data members
- Setting up a result visualizer
- Planning with BFS
- Planning with DFS
- Planning with A*
- Planning with Value Iteration
- Learning with Q-Learning
- Learning with Sarsa(λ)
- Live Visualization
- Value Function and Policy Visualization
- Experimenter Tools and Performance Plotting
- Conclusion
You are viewing the tutorial for BURLAP 1; if you'd like the BURLAP 2 tutorial, go here.
Introduction
The purpose of this tutorial is to get you familiar with using some of the planning and learning algorithms in BURLAP. Specifically, this tutorial will cover instantiating a GridWorld domain bundled with BURLAP, creating a task for it, having the task solved with Q-learning, Sarsa learning, BFS, DFS, A*, and Value Iteration. The tutorial will also show you how to visualize these results in various ways using tools in BURLAP. The take home message you should get from this tutorial is that using different planning and learning algoritms largely amounts to just changing the algorithm object you instantiate, with everything else being the same. You are encouraged to extend this tutorial on your own using some of the other planning and learning algorithms in BURLAP.
At the conclusion section of this tutorial, you will find all of the code we created, so if you'd prefer to jumpt right in, only coming back to this tutorial as questions arise, feel free to do so!
Creating the class shell
For this tutorial, we will start by making a class that has data members for all the domain and task relevant properties. In the tutorial we will call this class "BasicBehavior" but feel free to name it to whatever you like. Since we will also be running the examples from this class, we'll include a main method.
import burlap.behavior.singleagent.*;
import burlap.domain.singleagent.gridworld.*;
import burlap.oomdp.core.*;
import burlap.oomdp.singleagent.*;
import burlap.oomdp.singleagent.common.*;
import burlap.behavior.statehashing.DiscreteStateHashFactory;
public class BasicBehavior {
GridWorldDomain gwdg;
Domain domain;
StateParser sp;
RewardFunction rf;
TerminalFunction tf;
StateConditionTest goalCondition;
State initialState;
DiscreteStateHashFactory hashingFactory;
public static void main(String[] args) {
//we'll fill this in later
}
}
If you're already familiar with MDPs in general, the importance of some of these data members will be obvious. However, we will walk through in detail what data member is and why we're going to need it.
GridWorldDomain gwdg
This object is a DomainGenerator provided in the domains package. We will use this
object to create a basic grid world domain for our demonstration.
Domain domain
The domain object is an fundamental OO-MDP object. The domain object defines a set of
attributes, object classes, propositional functions, and actions (along with the actions transition dynamics). You
can imagine domain objects as holding information regarding how states in a problem are represented
and how the physics of the problem work.
StateParser sp
A StateParser object is used to convert OO-MDP states to and from string representations.
This is useful
if you want to be be able to record planning and learning results to files, which we will be doing in this tutorial.
RewardFunction rf
A RewardFunction is an object that returns a double valued reward for any given state-action-state
sequence. This is a fundamental component of every MDP and its what an agent tries to maximize. That is, the goal
of an agent is acquire as much reward from the world as possible.
TerminalFunction tf
A common form of MDPs are episodic MDPs: MDPs that end in some specific state or set of states.
A typical
reason to define an episodic MDP is when there is a goal state the agent is trying to reach. In such cases, the goal
state is a terminal state, because once the agent reaches it, there is nothing left to do.
Inversely, some states may be fail states that prevent the agent continuing; these too would be terminal states.
There may also be other reasons to provide termination states, but whatever you reason may be, the
TerminalFunction object defines which states are terminal states.
StateConditionTest goalCondition
Not all planning algorithms are designed to maximize reward functions. Many
are instead defined as search algorithms that seek action sequences to reach specific goal states.
A StateConditionTest object operates much
like a TerminalFunction, only it can be used as a means to specify any kind of state check. In this tutorial we will
use it to specify goal states for planning algorithms that search for action sequences to reach goals rather than
planning algorithms that try to maximize reward.
State initialState
To perform any planning or learning, we will generally need to specify an initial state
from which to perform it. An OO-MDP state consists of an arbitrary set of instantiated object classes from a given
domain. An instantiated object of an object class means that there is a value is defined for each attribute of
the object class. A state may also consist of an arbitrary number of object instances for any given class, but in
some domains you may typically only have one instance for each. In the GridWorld domain, for instance, there will
be one instance of the agent object (which is defined by an x and y position) and one instance of a location object
(which is also defined by an x and y position),
which will be used to specify a goal location where the agent needs to go.
Note
Even when VI is passed an initial state it's possible for the state space to be infinite. For instance, perhaps there are actions in the domain that allow an indefinite number of new object instances to be created, or perhaps the values of object attributes are continuous with an infinite number of reachable values. The fact is that some problems are inherently infinite in their state space and Value Iteration isn't an algorithm that can handle these kinds of problems.
DiscreteStateHashFactory hasingFactory
To perform planning and learning, there will need to be some way
to look up previously examined states in data structures and to do so efficiently will require some way to compute
hash codes for states and to compare them for equality.
The DiscreteStateHashFactory provides a general means to do this for any discrete and non-relational
OO-MDP domain. A nice property of the DiscreteStateHashFactory object is that hashing results are invariant
to specific object references. For instance, consider a state (s0) with block objects defined by spatial position
information. Now imagine a new state (s1) that is the result of swapping the positions of the blocks objects.
Even though the object idenitifers associated with the block positions is different between s0 and s1,
these really are the same state. The below illustration helps clarify this property.
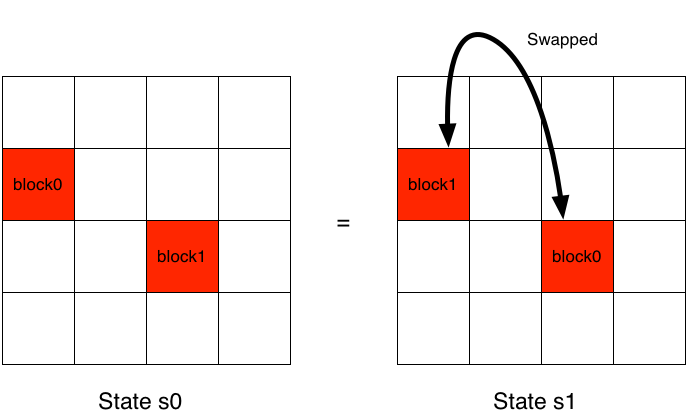
An advantage of the DiscreteStateHashFactory is that it will treat s0 and s1 identically; that is, it recognizes that s0 == s1 and the same hash code will also be computed for each state. In BURLAP, we refer to this kind of state invariance as object identifier invariance.
Note
There may be some problems in which you do not want to use object identifier invariance. For instance, maybe the task of a problem is to move a specific block to a specific location and it does matter which block is in that location. For such a task, using object identifier invariance will break the planning/learning algorithms ability to correctly find the solution. In cases like these, a different state hashing factory should be used, such as NameDependentStateHashFactory. The Power of the StateHashFactory objects is that you can define your own new equality and hashing mechanisms for states and simply pass them along to your planning and learning algorithm.