Tutorial: Solving Continuous Domains
Tutorials (v1) > Solving Continuous Domains > Part 3
Solving Lunar Lander with SARSA(λ)
In our final example of this tutorial we will solve a simplified Lunar Lander domain using gradient descent Sarsa Lambda and CMAC/Tiling coding basis functions. The Lunar Lander domain is a simplified version of the classic 1979 Atari arcade game by the same name. In this domain the agent pilots a ship that must take off from the ground and land on a landing pad. The agent can either use a strong rocket thruster to push the ship in the direction the ship is facing, use a weak rocket thruster that is equal magnitude to the force of gravity, rotate clockwise or counterclockwise, or coast. The agent will receive a large reward for landing on the landing pad, a large negative reward for colliding with the ground or an obstacle, and a small negative reward for all other transitions.
As with the previous examples, let us begin by making a method for this example (LLSARSA) and instantiating a Lunar Lander domain, task, and initial state.
import burlap.domain.singleagent.lunarlander.LLStateParser; import burlap.domain.singleagent.lunarlander.LunarLanderDomain; import burlap.domain.singleagent.lunarlander.LunarLanderRF; import burlap.domain.singleagent.lunarlander.LunarLanderTF;
public static void LLSARSA(){
LunarLanderDomain lld = new LunarLanderDomain();
Domain domain = lld.generateDomain();
RewardFunction rf = new LunarLanderRF(domain);
TerminalFunction tf = new LunarLanderTF(domain);
StateParser sp = new LLStateParser(domain);
State s = LunarLanderDomain.getCleanState(domain, 0);
LunarLanderDomain.setAgent(s, 0., 5.0, 0.0);
LunarLanderDomain.setPad(s, 75., 95., 0., 10.);
}
Most of this code should be fairly self explanatory. Using a default construct for LunarLanderDomain and not setting anything else with it will use default parameters for the domain (but you can change various properties such as the force of gravity, thrust, etc.). The default reward function returns +1000 for landing, -100 for collisions, and -1 for regular transitions (though these values can be changed with a different constructor). The terminal function sets all states in which the ship has landed on the landing pad as terminal states. The getCleanState method, with the parameter 0 creates a state with an agent object (the ship) a landing pad object, and 0 obstacle objects. The setAgent method parameters specify the angle of the ship from the vertical axis in radians, the x position of the ship (5), and the y position of the ship (0, on the ground), respectively. The setPad method parameters define the landing pad dimensions in terms of the rectangular left, right, bottom, top boundaries, respectively. This will create an initial state that looks like the below (as visualized in BURLAP).
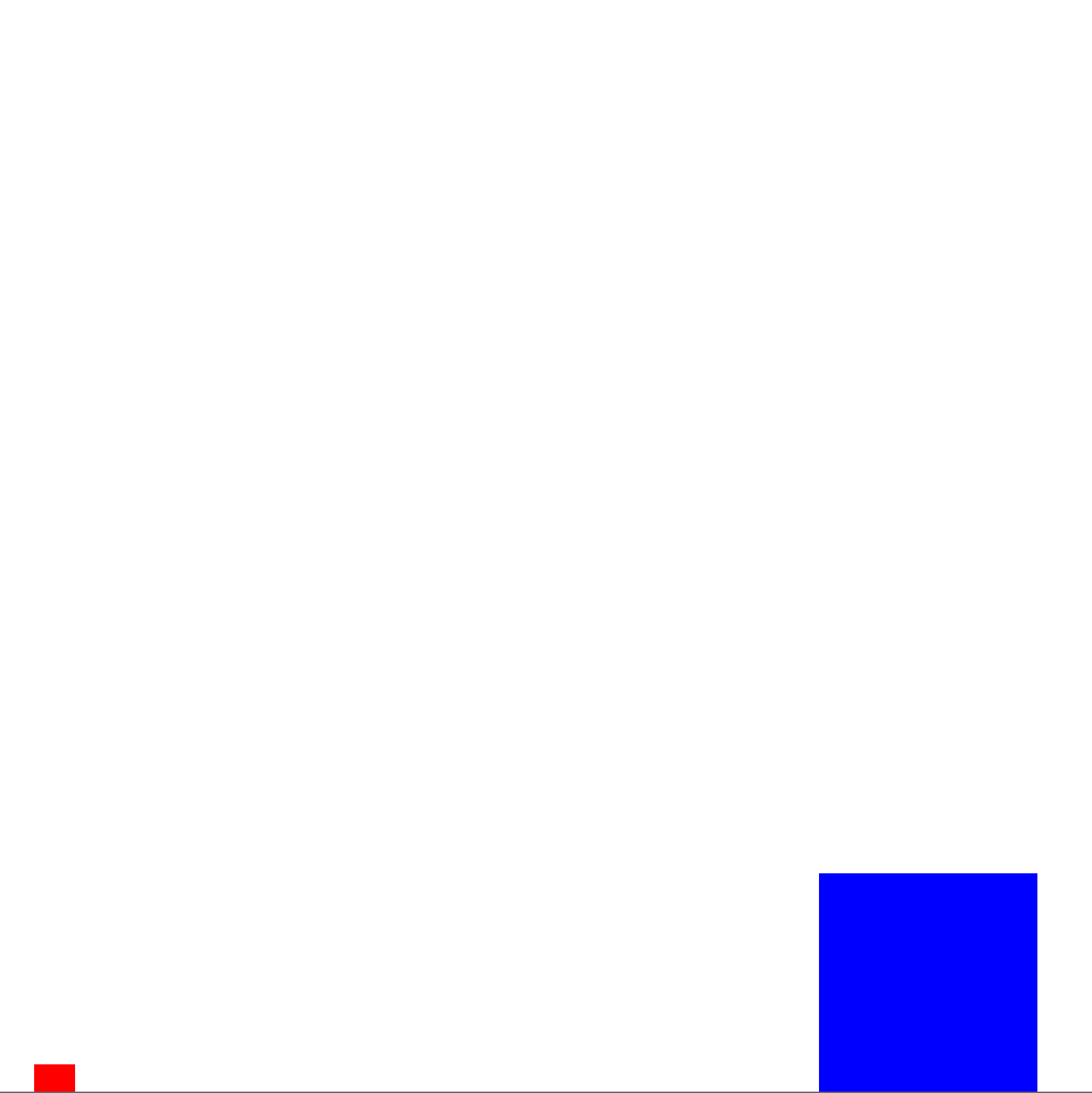
The initial stated used in Lunar Lander. The red box is the ship, the blue box the landing pad.
We're going to solve this problem with gradient descent SARSA(λ), which is a learning algorithm that behaves much like conventional tabular SARSA(λ) (discussed in previous tutorials), except it learns an approximation of the value function, much like LSPI. Unlike LSPI, gradient descent SARSA(λ) does not need to use a linear approximator; however, in practice it is usually a good idea to use a linear approximator because there are much stronger learning convergence guarantees with linear approximators. When using a linear approximator, it is as with LSPI, a good idea then to use some kind of basis functions. Like in the LSPI example, we could use the same Fourier basis or radial basis functions for gradient descent SARSA(λ). However, this time we'll use a different basis function: CMACs, also know in reinforcement learning literature as Tile Coding.
CMACs address learning in continuous domains in a only slightly more complex way than merely discretizing the state space, yet also diminish the aliasing effects that discretization can incur. To describe how they work, lets start by thinking about how a state discretization can be used to create a set of binary basis functions. First imagine a discretization of the state space as a process that creates large bins, or tiles, across the entire state space. We'll let each tile represent a different binary basis function. For a given input continuous state, all basis functions return a value of 0, except the function for the tile in which the continuous state is contained, which will return a value of 1. By then estimating a linear function over these features, we generalize the observed rewards and transitions for one state to all states that are contained in the same tile; the larger the tiles we use, the larger the generalization. A disadvantage of using such a simple discretization is that it produces aliasing effects. That is, two states may be very similar but reside on opposite sides of the edge of a tile, which results in none of their experience being shared, despite the fact that they are similar and do share experiences with other states that are more distant but happen to be in the same tile.
CMACs diminish this aliasing effect by instead creating multiple offset tilings over the state space and creating a basis function for each tile in each of the tilings. If there are n tilings, then any given input state will have n basis functions with a value 1 (one for the tile in which the query state is contained for each tiling). Because the tilings are offset from each other, two states may be contained in the same tile of one tiling, but in different tiles for a different tiling. As a consequence, experience generalization still occurs between states in the same tiling, but the differences between different tilings regains specificity and removes aliasing effects. For more information on CMACs with some good illustrations, we recommend the Generalization and Function Approximation chapter in the book Reinforcement Learning: An Introduction, by Sutton and Barto. An online version of the chapter can be found here.
An advantage of using CMACs is that you only need to store weight values in the fitted linear function for tiles that are associated with states that the agent has experienced thus far (the basis function for all other tiles would return a value of zero and therefore contribute nothing to the value function approximation). Another advantage specific to OO-MDPs is that because each tile represents a discretized state, we can maintain object identifier independence, which is otherwise not always possible to do with a number of value function approximation methods. If you don't need object identifier independence, there is another implementation of CMACs in BURLAP called FVCMACFeatureDatabase that is slightly more CPU efficient and operates on state feature vectors (which as before are produced with StateToFeatureVectorGenerator objects). For this tutorial, however, we will use the version that provides object identifier independence, which is called CMACFeatureDatabase.
Lets continue our code implementation by instantiating a CMACFeatureDatabase object and defining the tiling of our state space. To implement CMAC basis functions, we will need to decide on the number of tilings that we use and the width of each tile along each attribute. In this case, we will use 5 tilings with a width for each attribute that produces 10 tiles along each attribute range. We will limit this tiling to the Lunar Lander ship attribute values and ignore attributes for the landing pad. Since the agent's ship is defined by 5 attributes (x position, y position, x velocity, y velocity, and rotation angle from the vertical axis), this will produce 5 tilings that each define at most 10^5 tiles (again though, we don't necessarily have to store weights for all tiles if the agent never visits them!) To do so, add the below code.
import burlap.behavior.singleagent.vfa.cmac.CMACFeatureDatabase;
int nTilings = 5;
CMACFeatureDatabase cmac = new CMACFeatureDatabase(nTilings,
CMACFeatureDatabase.TilingArrangement.RANDOMJITTER);
double resolution = 10.;
double angleWidth = 2 * lld.getAngmax() / resolution;
double xWidth = (lld.getXmax() - lld.getXmin()) / resolution;
double yWidth = (lld.getYmax() - lld.getYmin()) / resolution;
double velocityWidth = 2 * lld.getVmax() / resolution;
cmac.addSpecificationForAllTilings(LunarLanderDomain.AGENTCLASS,
domain.getAttribute(LunarLanderDomain.AATTNAME),
angleWidth);
cmac.addSpecificationForAllTilings(LunarLanderDomain.AGENTCLASS,
domain.getAttribute(LunarLanderDomain.XATTNAME),
xWidth);
cmac.addSpecificationForAllTilings(LunarLanderDomain.AGENTCLASS,
domain.getAttribute(LunarLanderDomain.YATTNAME),
yWidth);
cmac.addSpecificationForAllTilings(LunarLanderDomain.AGENTCLASS,
domain.getAttribute(LunarLanderDomain.VXATTNAME),
velocityWidth);
cmac.addSpecificationForAllTilings(LunarLanderDomain.AGENTCLASS,
domain.getAttribute(LunarLanderDomain.VYATTNAME),
velocityWidth);
In the first line, we instantiate the CMACFeatureDatabase with 5 tilings, each offset by a random amount. Then we compute tile widths along each attribute such that it would produce at most 10 tile margins along each attribute. The methods lld.getXMin() simply return the minimum x-value for our LunarLander instance (and the other methods return their respective attribute's value ranges). Finally, we inform the CMACFeatureDatabase of the width for each attribute that will be included in the tiling for each object class. In this case, we will only produce tilings over the agent class for its rotation angle; x, y position; and x, y velocity attributes and ignore the attributes for other object classes like the landing pad.
Now that we have the CMACFeatureDatabase set up, we can create a linear value function approximator for it and pass it along to gradient descent SARSA(λ).
import burlap.behavior.singleagent.learning.tdmethods.vfa.GradientDescentSarsaLam;
double defaultQ = 0.5;
ValueFunctionApproximation vfa = cmac.generateVFA(defaultQ/nTilings);
GradientDescentSarsaLam agent = new GradientDescentSarsaLam(domain, rf, tf,
0.99, vfa, 0.02, 10000, 0.5);
Note that to set the initial default Q-values to be predicted to 0.5, we set the value of each feature weight to 0.5 divided by the number of tilings. We divide the desired initial Q-value (0.5) by the number of tilings (5), because for any given state there will only be n features with a value of 1 and the rest 0, where n is the number of tilings. Therefore, if the initial weight value for all those features is 0.5/5, the linear estimate will predict our desired initial Q-value: 0.5. We also set the learning rate for gradient descent SARSA(λ) to 0.02 (in general, you should decrease the learning rate as the number of features increases), set a maximum learning episode size of 10000, and set λ to 0.5.
With gradient descent SARSA(λ) instantiated, we can run learning episodes just like we do for typical SARSA(λ). Lets run learning for 5000 episodes, record the episodes to files, and then visualize the results with an EpisodeSequenceVisualizer.
import burlap.oomdp.visualizer.Visualizer;
for(int i = 0; i < 5000; i++){
EpisodeAnalysis ea = agent.runLearningEpisodeFrom(s); //run learning episode
ea.writeToFile(String.format("lunarLander/e%04d", i), sp); //record episode to a file
System.out.println(i + ": " + ea.numTimeSteps()); //print the performance of this episode
}
Visualizer v = LLVisualizer.getVisualizer(lld);
new EpisodeSequenceVisualizer(v, domain, sp, "lunarLander");
If you now point your main method to LLSARSA() and run it, you should initially see a punch of text after each episode stating how long the learning episode lasted followed by the EpisodeSequenceVisualizer GUI, which should look something like the below.
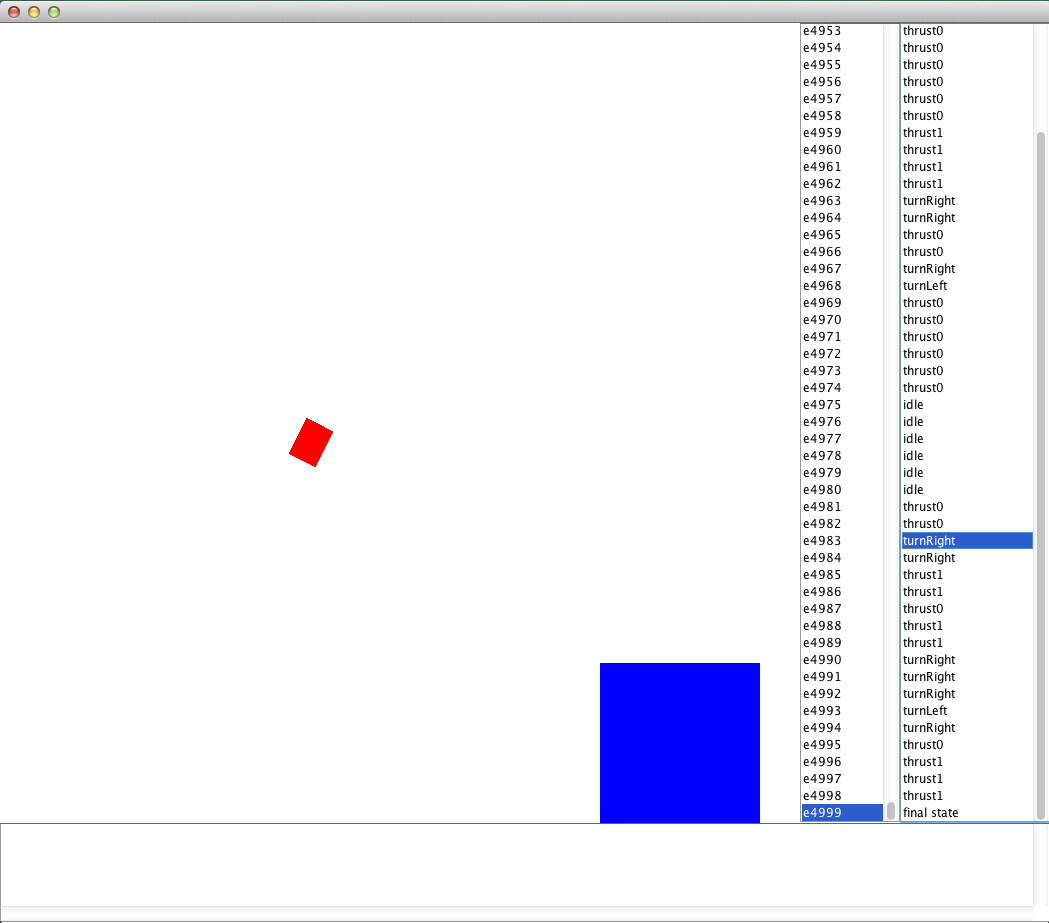
The EpisodeSequenceVisualizer GUI showing the learning results on Lunar Lander
You should find that as more learning episodes are performed, the agent becomes progressively better at piloting to the landing pad.
That concludes all of our examples for this tutorial! Closing remarks and the full code we created can be found on the next page.